Text Processing
This section contains information on how to configure text processing. Related options apply to:
- Best Bets
- Content Type Extension Mapping
- Content Type Extraction Methods
- Language Detection
- No Stem
- OCR Language Mapping
- Synonyms
- Text Patterns
Sometimes an application may wish to push selected documents to the top of a hitlist for specific queries. This may be implemented by specifying Best Bets for specific query text.
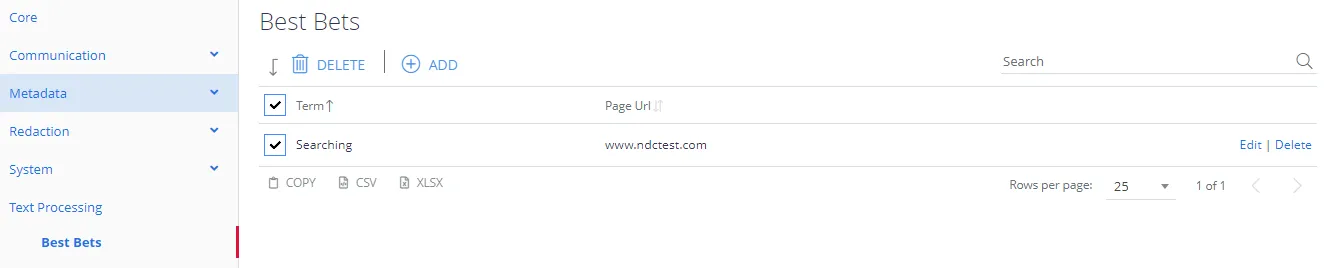
First, enter the search term that you wish to match and then click the Add button.
Next, click on the term, and specify one or more URLs that should appear at the top of the hit list.
Content Type Extension Mapping
Sometimes an organization may wish to process certain file types as a different content type. The primary use case for this is internal content types that map to a content type already understood / identified.
In this case the example has a .rpt file being treated as a text file, as such the file will be copied to a temporary location as a .txt file and processed as if it were any other text file.

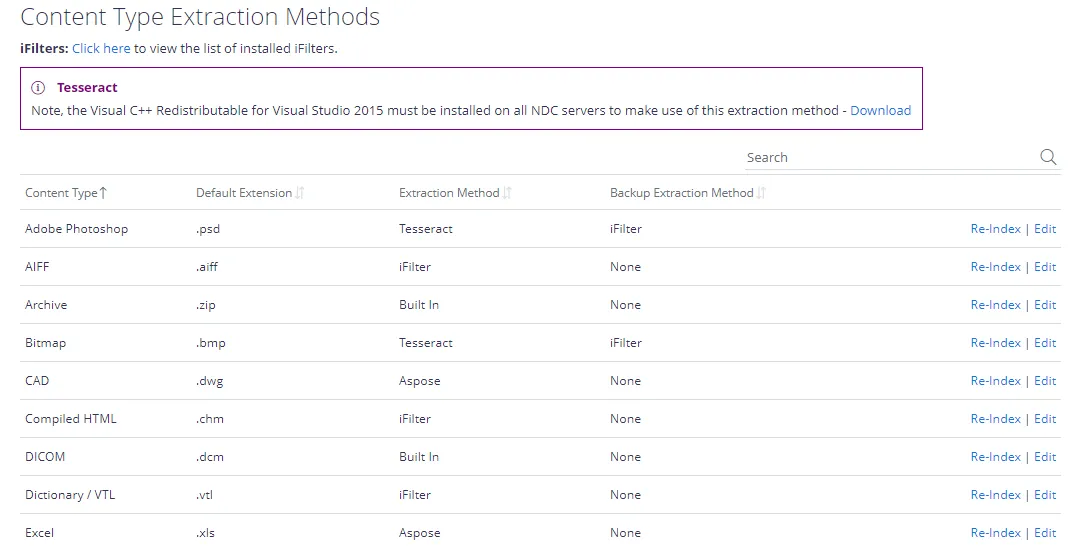
Content Type Extraction Methods
The Content Type Extraction methods describes how documents will be handled by the APIs and the core services. A number of built-in processing methods are available, where there is no available method the processing will default to running through standard Microsoft Search iFilter processing.
The methods can be easily altered by clicking Edit and then selecting the preferred processing method. It is also possible to specify that an iFilter should be utilised if the primary method fails to extract text from the document – the backup method will be used if the extraction fails to find more than 5 characters of text.
If you have updated the extraction method we recommend re-processing any documents that have already been processed to ensure consistency. Selecting Re-index from the grid for the affected content type will re-process the necessary records.
The language detection list specifies which languages will be considered for auto-detection.
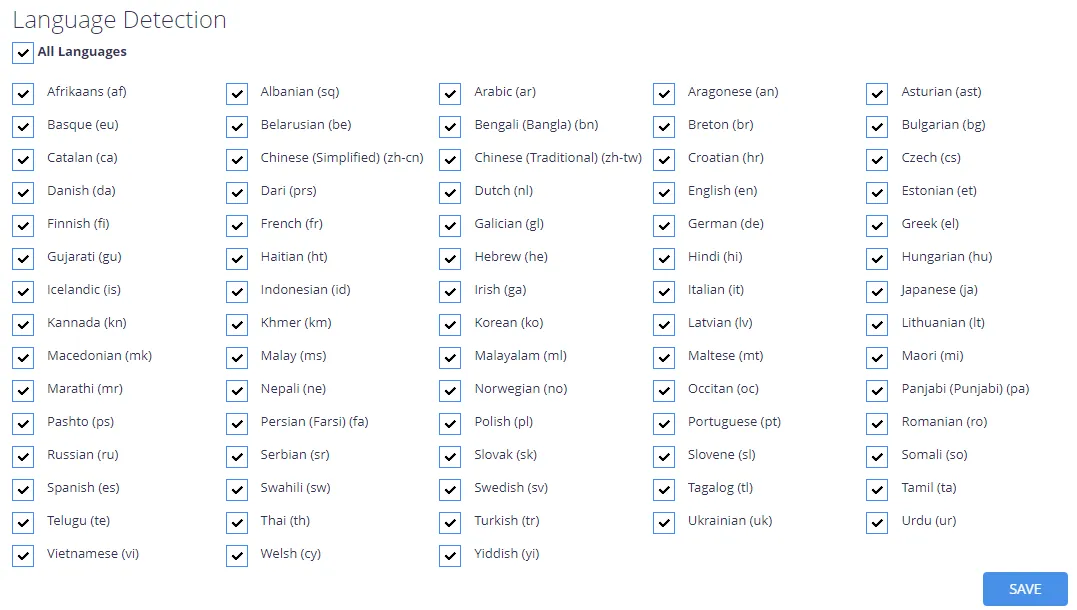
If a language is excluded then it cannot be used to identify the language of a document and it will be removed from the language options in Taxonomy Manager.
TIP: You can also OCR recognition for non-English images. Refer to the following Netwrix knowledge base article for more information: How to enable OCR for non-English images.
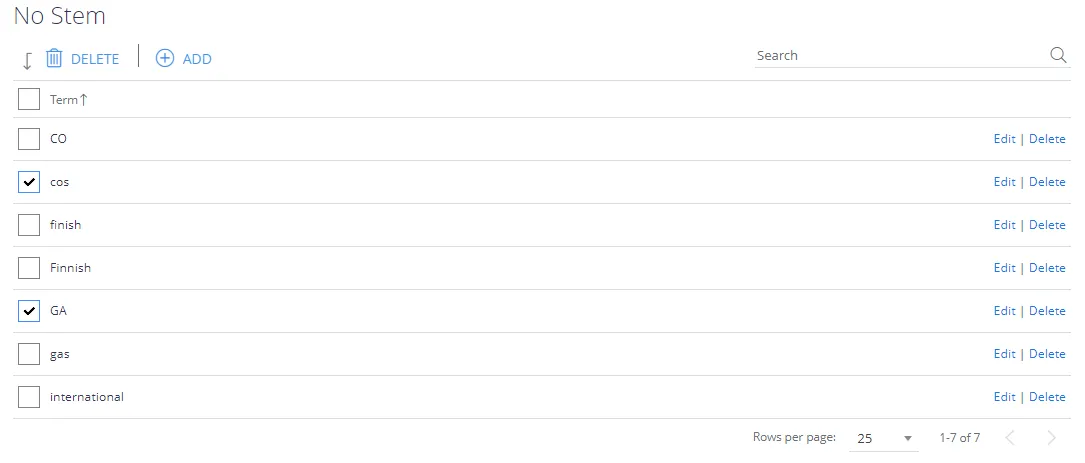
The No Stem list offers the ability to disable language stemming for a particular word or phrase, this supports the ability to always apply a phrasematch when a particular term is used as either a clue – or a search term.
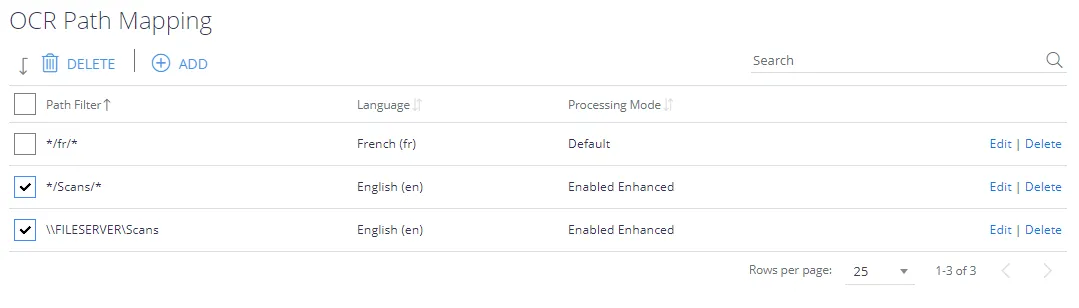
The OCR language mapping configuration screen can be used if you wish to OCR non-English images via Tesseract. File paths (including parts of paths) can be mapped to specific Tesseract language packs.
Often it is important to submit a query and have synonyms automatically included. A generic set of synonyms may be configured by using the Synonyms form.

Many HTML web pages contain navigation information and other extraneous information that is the same for all pages and/or not relevant to the individual page content. If all of the text is indexed from these HTML pages then this can lead to unwanted search results where a match is made, for example, to an entry in a standard page navigation area.
The Text Patterns feature is provided to assist with the cleanup of HTML documents. TextPatterns can also be used to index terms that would normally be discarded.

The StartTag and EndTag values are case sensitive strings used to identify the content to be managed, the content is then managed based on the filter type.
There are three tag types that can be used to assist in the cleanup:
- FILTER—Extracts a subset of the HTML page, prior to extracting the plain text. Only a single section will be extracted for each TextFilter processed.
- DELETE—Deletes sections of the HTML page, prior to extracting the plain text.
- INDEX TERM (EndTag ignored)—Create index terms that would otherwise not be formed. For example the term “E.ON” is a useful one for people interested in energy companies. However, this term would not normally be created because a full stop normally acts as a term separator. However, if we create an INDEX TERM for this pattern then it will be detected and indexed as required.