Configuration Options
The Config administration area allows you to specify global system configuration settings. The default screen shows the most commonly amended settings.
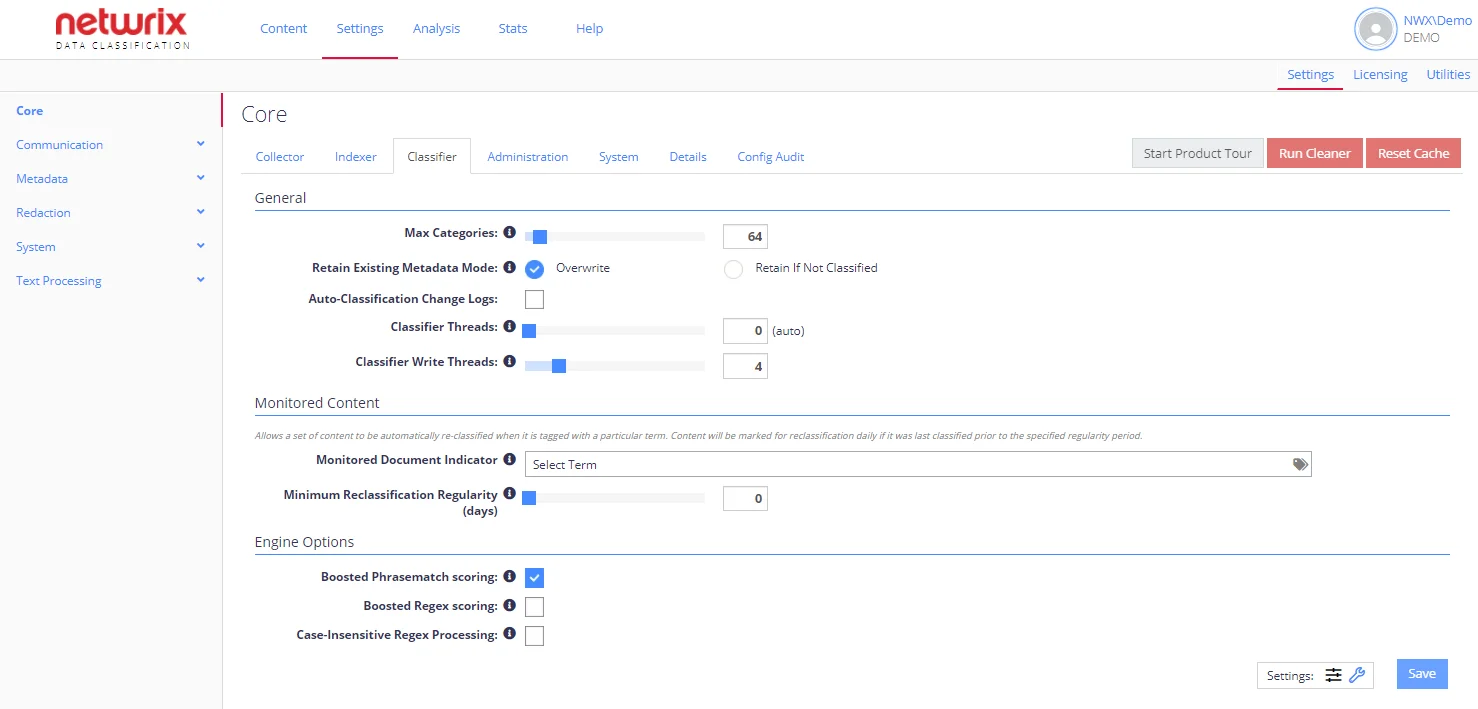
The most frequently used settings are displayed by default. Some configuration options are hidden and can be shown by selecting the Advanced Settings ("wrench" icon). Note that they will be only available See Users and Security Settings for more information.
See next:
- Core Configuration
- Communication Settings
- Metadata Configuration
- Redaction
- System Configuration Settings
- Text Processing
- MIP Labels Configuration
- Language Stemming
Redaction
This section contains information on configuring redaction plans and entities. Review the following for additional information:
Redaction Plans
Redaction plans can be used as an optional migration step to remove specific entities from supported content types. During the migration of a document a migration plan will remove the following entity types (depending on the configuration):
-
NLP Entities—Items identified by the NLP entity extraction, such as names or locations
-
Regex Entities—Items identified by the Regex classification clues, such as credit card numbers or social security numbers
- Specific clues can be skipped as part of a redaction plan by specifying Excluded Clues, such as: “VISA” or “SSN” (matched to the term name)
-
Custom Entities—Any custom words or phrases associated with the plan.
Masking based redaction will ensure that a specified number of start / end characters will be retained from each redacted value.

Redaction Entity Groups
Entity Groups can be used to add redaction entities to specific groups.

Redaction Entities
Entities can be used to specify any custom words or phrases that should be removed by a redaction plan.

System Configuration Settings
This section contains information on additional configuration settings specific to different source types.
AD Domains Excluded
The AD Domains Excluded list is used to disable Active Directory expansion for certain domain names. This is useful in a multi-Domain forest, where the Netwrix Data Classification server does not have access to all domains within the forest.

Attachments Excluded
When indexing files from that potentially contain attachments (SharePoint List Items) the list of file locations that will be ignored is defined by the Attachments Excluded list. The definitions in this list may be viewed and modified via the Attachments Excluded form:

Any file with a path that matches one of these patterns will be ignored. Wildcards may be used anywhere in the pattern definition, with:
- The asterisk character (*) matching any sequence of characters
- The question mark character (?) matching any single character
No Index
Sometimes an application may wish to remove selected documents from all search results. This may be implemented by specifying No Index entries.
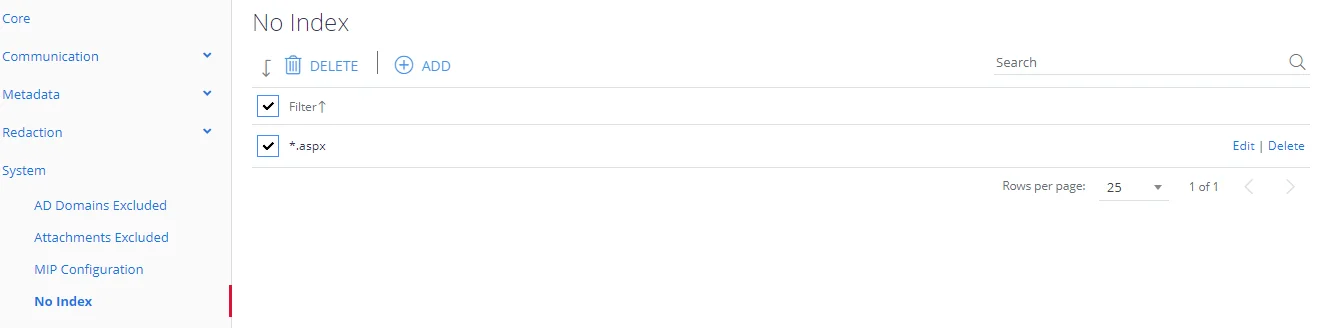
Any number of URLs (or Filenames) may be entered and none of these will ever appear in search results. Wildcards may be used anywhere in the pattern definition, with:
- The asterisk character (*) matching any sequence of characters
- The Question mark character (?) matching any single character
Proxy Server
The Proxy Server form may be used to define a proxy server to be used when crawling websites, the proxy server is not used for SharePoint crawling.

Set Bypass Local to Yes to bypass the proxy server for local addresses (localhost etc).
Any other exclusions that should not go through the proxy server should be defined in the Exceptions list.
Suspend Services (Scheduler)
All Netwrix Data Classification services run as Windows services. They are responsible for building the search index and classifying documents against the registered taxonomies.
It can be useful to suspend these services from running so that they do not impact query performance during the peak hours of the working day. Sometimes it may be useful to suspend these services for some lower priority sources but have them continue to process higher priority sources.
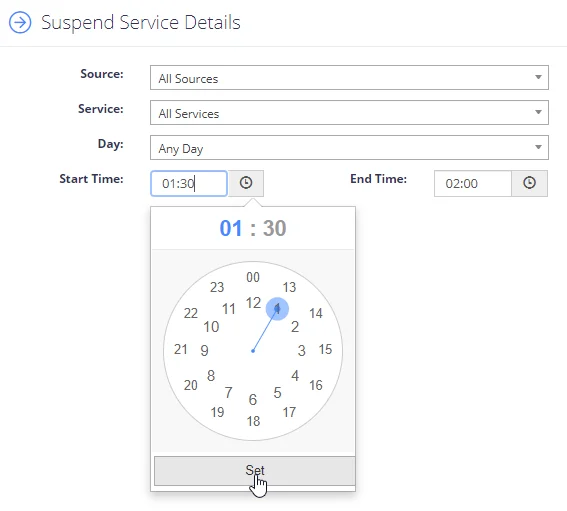
Service suspensions can be configured in the following ways:
- Source—Which source types the suspension is in place for: all source types, specific source types (SharePoint, Web etc) or specifically against Re-Indexing operations.
- Service—Which services are affected by the suspension: All Services, or, a choice of: NDC Collector, NDC Indexer, NDC Classifier.
- Day/Times—Allows the configuration of which days and times the suspension will be in place.
Text Processing
This section contains information on how to configure text processing. Related options apply to:
- Best Bets
- Content Type Extension Mapping
- Content Type Extraction Methods
- Language Detection
- No Stem
- OCR Language Mapping
- Synonyms
- Text Patterns
Best Bets
Sometimes an application may wish to push selected documents to the top of a hitlist for specific queries. This may be implemented by specifying Best Bets for specific query text.
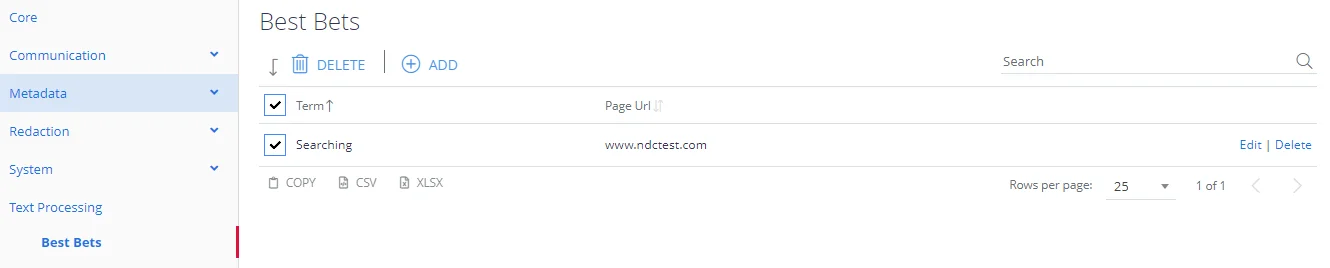
First, enter the search term that you wish to match and then click the Add button.
Next, click on the term, and specify one or more URLs that should appear at the top of the hit list.
Content Type Extension Mapping
Sometimes an organization may wish to process certain file types as a different content type. The primary use case for this is internal content types that map to a content type already understood / identified.
In this case the example has a .rpt file being treated as a text file, as such the file will be copied to a temporary location as a .txt file and processed as if it were any other text file.

Content Type Extraction Methods
The Content Type Extraction methods describes how documents will be handled by the APIs and the core services. A number of built-in processing methods are available, where there is no available method the processing will default to running through standard Microsoft Search iFilter processing.
The methods can be easily altered by clicking Edit and then selecting the preferred processing method. It is also possible to specify that an iFilter should be utilised if the primary method fails to extract text from the document – the backup method will be used if the extraction fails to find more than 5 characters of text.
If you have updated the extraction method we recommend re-processing any documents that have already been processed to ensure consistency. Selecting Re-index from the grid for the affected content type will re-process the necessary records.

Language Detection
The language detection list specifies which languages will be considered for auto-detection.
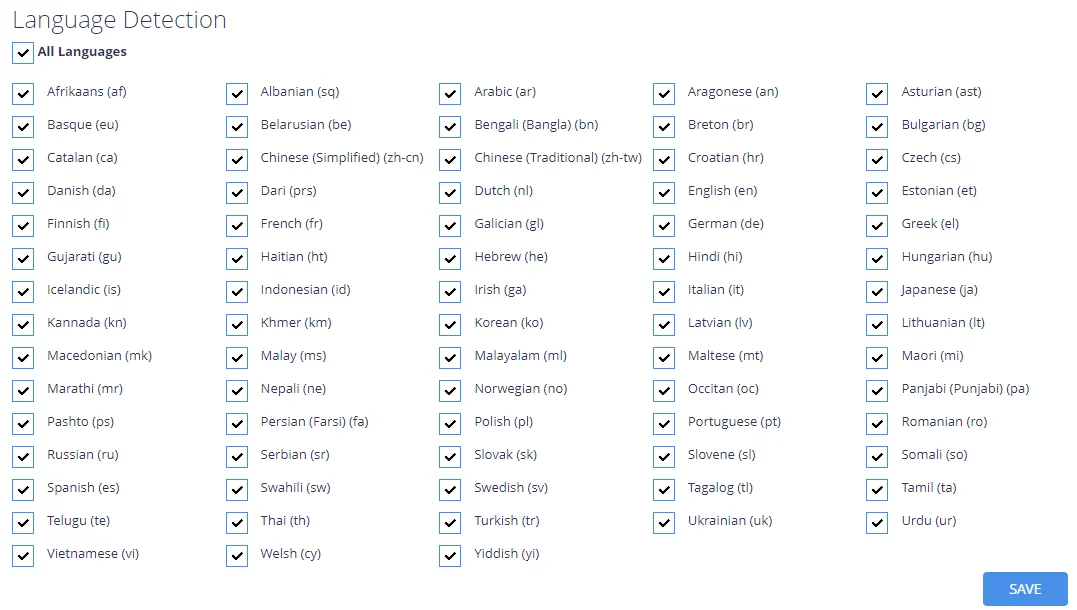
If a language is excluded then it cannot be used to identify the language of a document and it will be removed from the language options in Taxonomy Manager.
TIP: You can also OCR recognition for non-English images. Refer to the following Netwrix knowledge base article for more information: How to enable OCR for non-English images.
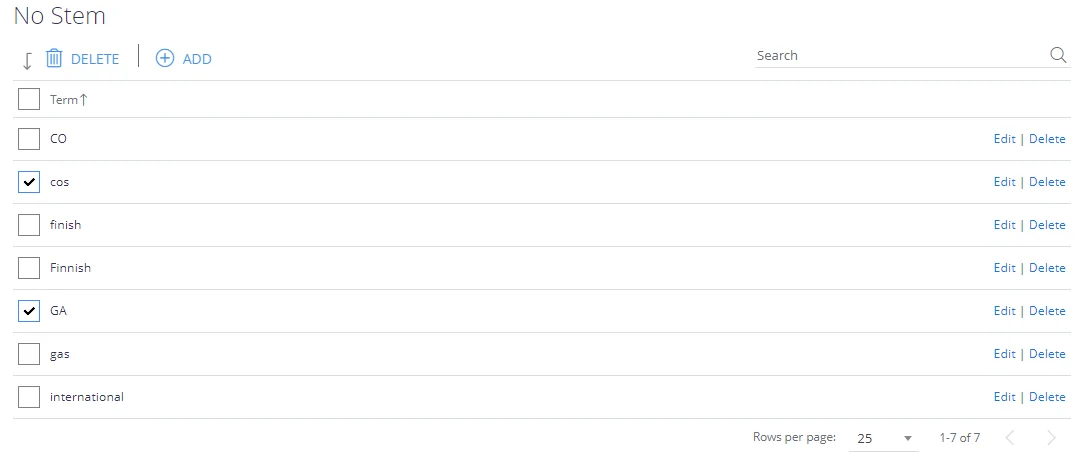
No Stem
The No Stem list offers the ability to disable language stemming for a particular word or phrase, this supports the ability to always apply a phrasematch when a particular term is used as either a clue – or a search term.
OCR Language Mapping
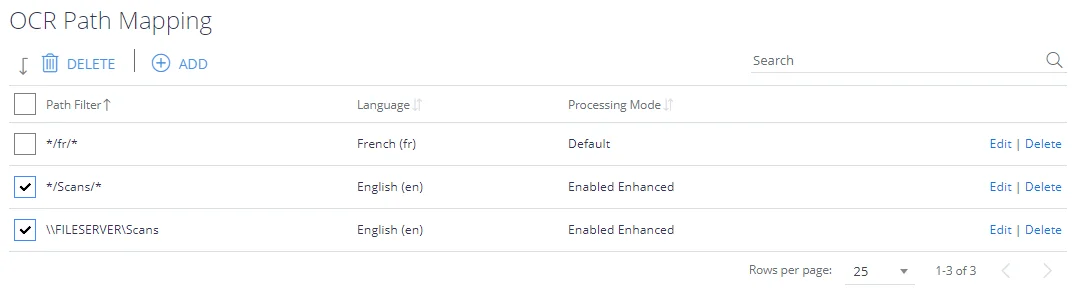
The OCR language mapping configuration screen can be used if you wish to OCR non-English images via Tesseract. File paths (including parts of paths) can be mapped to specific Tesseract language packs.
Synonyms
Often it is important to submit a query and have synonyms automatically included. A generic set of synonyms may be configured by using the Synonyms form.

Text Patterns
Many HTML web pages contain navigation information and other extraneous information that is the same for all pages and/or not relevant to the individual page content. If all of the text is indexed from these HTML pages then this can lead to unwanted search results where a match is made, for example, to an entry in a standard page navigation area.
The Text Patterns feature is provided to assist with the cleanup of HTML documents. TextPatterns can also be used to index terms that would normally be discarded.

The StartTag and EndTag values are case sensitive strings used to identify the content to be managed, the content is then managed based on the filter type.
There are three tag types that can be used to assist in the cleanup:
- FILTER—Extracts a subset of the HTML page, prior to extracting the plain text. Only a single section will be extracted for each TextFilter processed.
- DELETE—Deletes sections of the HTML page, prior to extracting the plain text.
- INDEX TERM (EndTag ignored)—Create index terms that would otherwise not be formed. For example the term “E.ON” is a useful one for people interested in energy companies. However, this term would not normally be created because a full stop normally acts as a term separator. However, if we create an INDEX TERM for this pattern then it will be detected and indexed as required.
System Configuration
System Configuration section in Netwrix Data Classification management console includes Config and Users areas:
- To specify Netwrix Data Classification settings and manage licenses, click Config.
- To set up user roles and security privileges, click Users.

See next: